
Best performance per Watt and per dollar
Kalray’s data processing units deliver exceptional performance and energy efficiency for AI/ML workloads. Available in the U.S. through our partnership.
Power-efficient dataflow acceleration — Kalray DPUs
When GPUs are overkill (or over budget) for streaming, signal, and pre/post-processing, Kalray’s MPPA™ Data Processing Units deliver GPU-class throughput at a fraction of the watts—with deterministic latency. With the Brane SDK, you develop and orchestrate DPUs alongside CPUs/GPUs from a single environment. As Kalray’s official U.S. partner, Brane provides local availability, integration, and support.
Perf / Watt Advantage
Many-core architecture and efficient on-chip fabric deliver high throughput at low power—shift streaming ops off the GPU and cut watts.
Deterministic Pipelines
Predictable latency and QoS for real-time agents, vision, and edge deployments—ideal for pre/post-processing and data movement.
Develop Once, Orchestrate Anywhere
Brane SDK unifies CPU/GPU/DPU workflows—build, debug, and schedule in one toolchain with flexible programming models.
Kalray’s MPPA™ Data Processing Units are programmable, many-core processors built for dataflow work—streaming I/O, pre/post-processing, filtering, vector ops, and movement. They deliver high, predictable throughput at lower power, keeping GPUs focused on math.
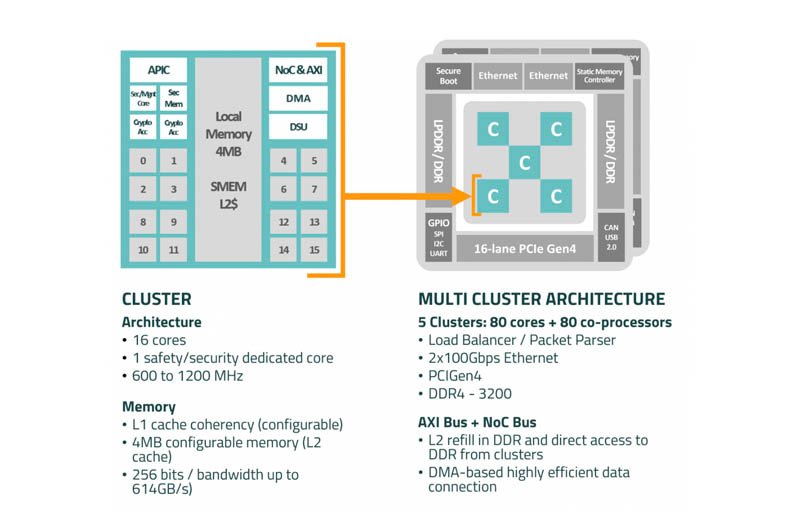
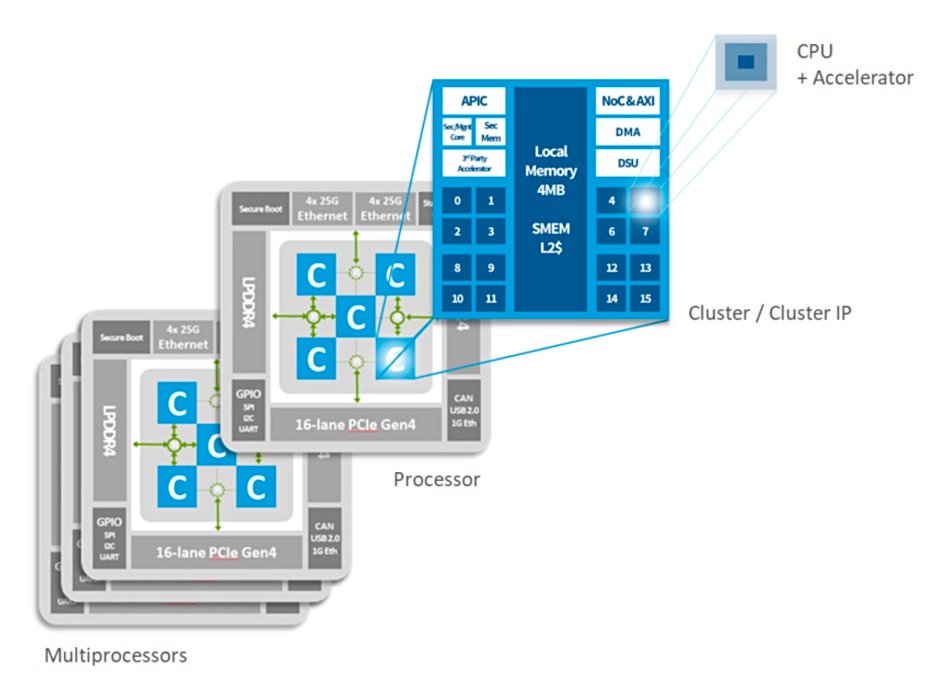
Kalray MPPA™ — what it brings
- Many-core parallelism: on-chip network + clusters keep multiple pipelines running concurrently.
- Deterministic latency: predictable QoS for real-time and edge agents.
- Perf per watt: offload tokenization, packing, codec, vector search, compression, and data movement.
- Unified dev: C/C++ on Linux; orchestrate CPU/GPU/DPU with the Brane SDK.
Dataflow & Streaming
Real-time & Control
AI Pipelines
Performance
Reliability
Control
Featured Kalray Accelerators
Kalray MPPA™ acceleration cards deliver flagship-tier throughput in dataflow pipelines at a fraction of the power — ideal for AI pre/post-processing, streaming I/O, and vector workloads.
Kalray K300 — MPPA®3-80
Low Power
Storage-centric acceleration card optimized for NVMe fan-out and high-throughput I/O operations. Perfect for data-intensive applications requiring massive parallel storage access with minimal power consumption.
Key Specifications
- Processor: Kalray MPPA®3-80 V1.2 @ 1 GHz
- Storage fan-out: up to 24 × 30 TB NVMe SSD
- Interfaces: PCIe Gen4 x16; 2 × QSFP28 100 GbE
- Throughput: up to 25 TFLOPS (FP16)
- Power: 36 W (typ.), 42 W (max)
Kalray TC4 — Quad MPPA®3-80
Multi-DPU
Quad-processor powerhouse delivering exceptional parallel processing performance for AI pipelines. Four MPPA®3-80 cores provide deterministic latency and massive throughput for demanding edge AI workloads.
Key Specifications
- Processors: 4 × Kalray MPPA®3-80 V1.2 @ 1 GHz
- Interfaces: PCIe Gen4 x16; 2 × QSFP28 100 GbE
- Throughput: up to 100 TFLOPS (FP16)
- Power: 60 W (typ.), 250 W (max)
- Manufactured in France (Asteelflash)
Need a different form factor or a custom integration? We also support additional Kalray configurations.
Contact UsKalray DPU — FAQ
The essentials on Kalray TC4 DPUs and how they slot into data-heavy AI pipelines.
What is a Kalray DPU?
A Data Processing Unit that offloads streaming, parsing, and data-movement tasks from CPUs/GPUs. Kalray’s MPPA® many-core design runs thousands of lightweight threads with predictable latency and strong perf per watt for I/O-bound pipelines.
Where does a DPU help the most?
Data ingest (video, telemetry), pre/post-processing (tokenization, compression, filtering), vector/RAG streaming, and network/IO handling. Offloading frees CPU/GPU cycles for model work.
Does a DPU replace my GPU?
No—it’s complementary. GPUs handle dense math for training/inference; the DPU accelerates the surrounding data pipeline to raise overall throughput per watt.
What are the core traits of the “Coolidge” processor?
Many-core compute clusters linked by an AXI fabric and RDMA-capable NoC for fast on-chip transfers, with memory/protection units for isolation and deterministic execution—useful at the edge.
Which OS and tools are supported?
Linux target. Kalray provides the low-level SDK/drivers; the Brane SDK offers containerized runners and orchestration so DPU stages can be invoked alongside CPU/GPU code from one environment.
How do we get started?
Share your pipeline stages (sources → transforms → sinks) and constraints (latency, power). We’ll map candidate stages to the DPU and set up a quick proof-of-value. Talk to an engineer.
Need help with Kalray Coolidge (TC4)?

Whether you’re getting started, porting operators or pipelines, or selecting the right board and sizing PCIe & power, we can help you move fast with a Linux-first setup and AccelOne SDK orchestration.
- Bring-up on Linux and SDK environment
- Porting data transforms, codecs, pre/post stages
- Board selection, bandwidth & power sizing
- Integration and proof-of-value flow